
4月9日aiXcoder宣布正式开源其7B模型Base版,仅仅过去一周,aiXcoder-7B在软件源代码托管服务平台GitHub上的Star数已超过2k。这是什么概念呢?GitHub托管了我们这个星球上最多的开放源代码的项目, 注册用户会为优秀的项目加星,类似朋友圈的点赞, Star数越多,说明项目越受欢迎,潜力也越大。目前GitHub托管了至少2800万开源代码库,根据公开资料显示,Star数大于1000占比不到0.1%。同时,跻身HuggingFace趋势榜单TOP30,令全球开发者瞩目。
aiXcoder-7B代码大模型一经开源,便迅速在开发者中掀起热潮。在GitHub上,除了类似“phenomenal”“wonderful work”的赞誉外,更多的是开发者们连珠炮式的提问——
“怎么在本地部署aiXcoder-7B,好用于生产环境?”
“我的机器配置很一般,有没有适合小内存设备的部署方案?”
“能否透露下aiXcoder的训练数据和关键技术,这款模型怎么做到如此强大?”
……
这些问题和需求,无不反映出开发者寄予的殷切厚望。对aiXcoder团队来说,能及时解答一线需求,无疑是最宝贵的馈赠。毕竟与开发者“零距离”接轨,听取痛点诉求,才是大模型不断进化、更好迭代的根本所在。
同时,aiXcoder-7B为开发者提供了丰富的二次创作空间,开放性和自由度直线拉满。项目上线伊始,就有众多开发者动手将模型成功本地部署,并在各种社交渠道分享了自己的部署经验和创作成果,帮助其他人快速上手。还有开发者则将aiXcoder-7B模型制作成了不同的GGUF格式文件,以适配多种硬件设备的使用需求。
不止如此,aiXcoder-7B还引来一群“自来水”开发者在社交媒体自发带货,AI科技博主World of AI在其YouTube视频中,盛赞“这是一个伟大的作品!”这位博主毫不吝惜溢美之词——“无与伦比的效率”“同类产品黯然失色”“前所未有的高度”等。
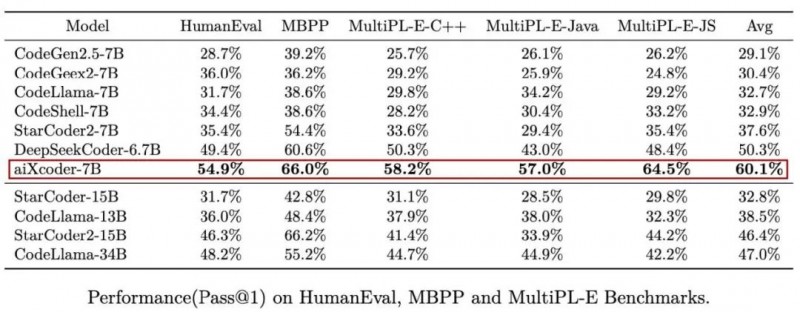
是什么让aiXcoder-7B 如此火爆?尽管这只是一个7B大小的模型,但在HumanEval、MBPP和MultiPL-E等主流代码生成评测集上,aiXcoder-7B均表现出了最佳成绩,甚至超越之前性能最佳的某34B模型,彰显了其卓越的代码生成与补全能力。
内力外功尽展锋芒,强悍实力全面征服开发者
aiXcoder-7B绝不是简单的“小身材、大能量”那么简单。这款代码大模型,在关键技术指标上也展现出了超乎寻常的实力。
首先,惊人的训练数据规模——1.2T规模的优质代码语料。这么庞大的训练集,确保了模型能够学习到丰富的编程知识和代码模式。这些训练数据并非简单拼凑,而是经过了精心的构建过程。团队针对数十种主流编程语言,对语料进行了语法分析,过滤掉了163种常见bug和197种代码缺陷。
其次,aiXcoder在预训练方法上求新求变。以前单纯的序列预训练很难有效捕捉代码的结构特征,而代码结构信息对于生成质量至关重要。为此,aiXcoder团队大胆尝试,将代码的抽象语法树结构融入到预训练过程中。这一创新大幅提升了模型对代码语义和逻辑的理解能力,从而确保生成高质量的代码。
拥有扎实的“内力”基础,aiXcoder-7B当然就展现出了令人赞叹的“外功”效果。无论是高效便捷的一键式代码生成服务,还是确保完整性的前提下结合长上下文和跨文件补全,它都让开发者有了全新的AI编程体验。
随着程序员思维的跳跃,一行行代码或主动生成,或灵活补全,犹如在屏幕上跳跃舞蹈,将编程变成一场人机合作的艺术。整个过程如此自然流畅,简直让人怀疑人工智能是否已经拥有了灵魂。诚然,这只是一种幻觉,aiXcoder团队显然正在朝这个方向不懈努力。
北大aiXcoder团队,软件尖兵打造的杰作
aiXcoder 团队来自北京大学软件工程研究所,他们不但是国际上最早将深度学习技术用于程序代码处理的团队,也是最早推出基于深度学习的编程产品的团队,从一开始他们就抓住并专注于代码大模型这个前沿赛道。
团队长期聚焦软件工程、系统软件、程序理解、程序生成、深度学习、可信人工智能等前沿领域,在多个国内外顶尖会议与期刊发表相关论文100余篇,多篇被国际同行视为“首创成果”。
从学界最前沿的理论研究,到广泛应用部署的商业实践,aiXcoder致力于将前沿人工智能技术应用于软件工程,聚焦代码大模型的企业个性化落地技术,助力企业实现智能化开发,为未来商业落地打下坚实基础。如今,这支科技尖兵已突出重围,继续书写一段人工智能与软件工程跨界融合的传奇。
一骑绝尘,企业级落地能力赋能行业应用
aiXcoder 在企业级应用场景下也毫不逊色,其一体化解决方案是企业安全与效率的最佳保障。
私有化部署是企业级客户普遍面临的一大难题。aiXcoder采用一系列先进的算法优化和架构调整,全面增强了模型在私有环境下的性能表现。借助其优化方案,企业无需购置高端GPU等专用硬件,就能利用现有算力资源在内网环境中部署大规模模型,实现与公有云同等的响应速度。
个性化训练是另一个行业难题。常规的微调方法不仅代价高昂,效果也往往不尽人意。aiXcoder拥有业内领先的个性化训练技术,核心方法是,一方面构建企业专属数据集和测评集,其中数据集构建基于企业代码特征和员工编程习惯,专门对代码及相关文档进行数据预处理;测评集构建则以真实开发场景为准绳,模拟并评估模型在实际应用中的预期效果。另一方面,将企业代码这一内因与企业算力资源这一外因相结合,充分考虑到不同企业计算资源、代码量的多寡,为他们提供灵活的个性化训练及优化方案,最大化提升专属代码大模型的前期训练效果和后续应用效果。
在传统行业数字化转型的重重考验下,aiXcoder代码大模型技术日益经受锻炼,不断优化完善。多年来,技术积累和产品驱动等一系列企业私有部署应用经验,为aiXcoder在市场推广奠定坚实基础。
软件自动化,未来更值得期待
如果说蒸汽机和发电机是人类从肌体劳动中解放出来的历史性变革,那么aiXcoder则是软件开发领域中的“新质生产力”最适合开发者的工具。
长期以来,编程工作一直是高度智力密集型的劳动。开发者需要在有限的时间和精力里,不断切换上下文、查阅文档、琢磨算法,并将这一切化作无数行晦涩的代码。即便是最优秀的程序员,其生产力提升也早已见顶。
aiXcoder-7B代码大模型的出现,让这一极限成为新的跳板,开发者将解放出更多精力投入设计和创新的核心环节。可以预见,这将带来软件开发流程的根本性重塑和生产率的几何级提升。凯文·凯利在2024年最新演讲中预言:“你暂时不会被AI替代,但会被更擅长使用AI的人替代。”对于公司、对于行业也是如此。
