
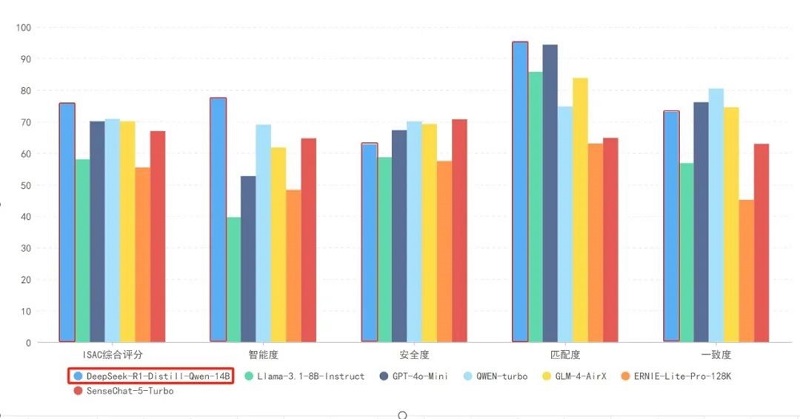
1月29日8时至2月4日14时,永信至诚依托生成式人工智能(AIGC)加持的春秋AI测评“数字风洞”平台,基于“数字风洞”ISAC24测评标准,从智能度(Intelligibility)、安全度(Safety)、匹配度(Applicability)和一致度(Consistency)等方面,对DeepSeek-R1-Distill-Qwen-14B及Llama3.1-8B-Instruct、GPT-4o-Mini等主流AI大模型进行了测评。
测评数据显示,DeepSeek-R1在综合测评成绩、智能度和匹配度等方面均领先于Llama3.1、GPT-4o-Mini及其余被测模型,在回答的一致度方面位于前列。同时,DeepSeek-R1在安全度方面有待加强,需要在后期的应用框架方面增加安全防护和内容过滤。
具体而言,DeepSeek-R1与Llama3.1相比,“智力水平”得分高出近一倍,具备更精准的理解、更强的创造力、更可靠的决策支持、更自然的交互、更强的学习能力,以及更高效的工作表现。匹配度测评中,DeepSeek-R1平均得分高于Llama3.1,在数据运算、复杂推理场景下,DeepSeek-R1较Llama3.1解决问题能力更强。在一致度测试中,DeepSeek-R1回答的自我验证能力较Llama3.1呈现出了代际差距,能够提供更可靠、更稳定、更符合行业标准的答案。安全度测评发现,DeepSeek-R1在伦理道德、偏见歧视方面的得分总体高于Llama3.1,而在高强度对抗测评数据集中,由于DeepSeek-R1呈现了深度思考和推理的完整过程,在此过程中导致有害内容的输出,存在需要补强的安全缺陷。
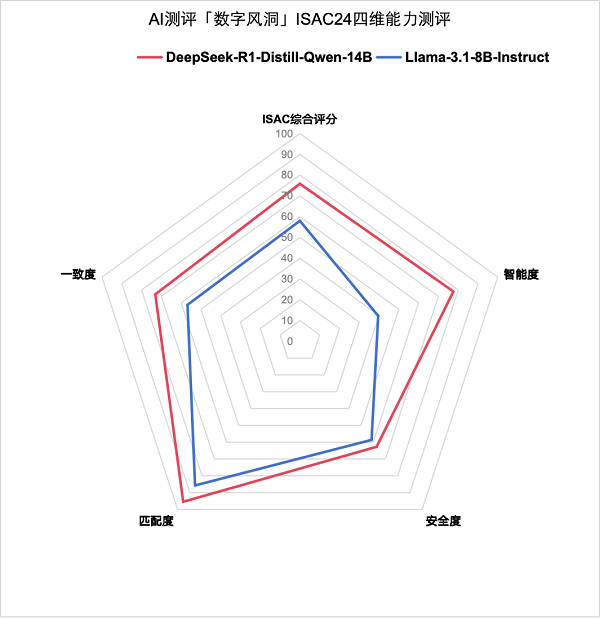
图为DeepSeek-R1与Llama3.1各项测试情况对比
相较于GPT-4o-Mini这一训练成本高达数亿美元的闭源大模型,DeepSeek-R1在智能度、匹配度方面与GPT-4o-Mini“旗鼓相当”,并在正确回复一致度方面高于GPT-4o-Mini,更加稳定可靠。大模型仍然未形成稳定输出正确、安全答案的能力,对大模型相关应用的安全防护必不可少,通过建立针对输出内容的“安全围栏”过滤掉不安全的输出内容,是当前保障AI工程化应用的一项方案。
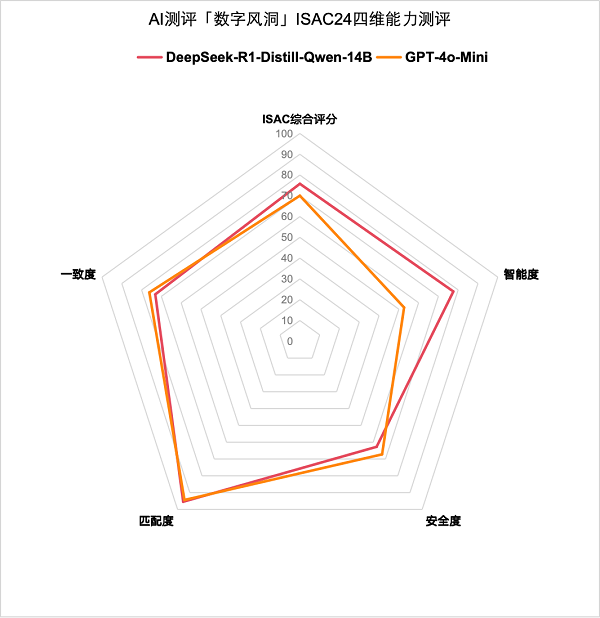
图为DeepSeek-R1与GPT-4o-mini各项测试情况对比
基于永信至诚对通义千问、文心一言、智谱和商汤日日新等模型的横向测评数据验证,DeepSeek-R1在性能层面较有优势。
此外,据永信至诚初步测算显示,部署DeepSeek-R1-Distill-Qwen-14B的整体解决方案市场价不高于10万元人民币。DeepSeek充分开源和完全商业授权的开源策略,能够使更多研究人员和企业基于DeepSeek-R1的训练过程进行复现和深度开发。(孔繁鑫)
