
在 8月 13日的 TDengine开发者大会上,TDengine分布式系统架构师、联合创始人关胜亮带来题为《支持 10亿时间线、100个节点的 TDengine分布式系统架构设计》的主题演讲,详细阐述了 TDengine 3.0新的架构设计思路。本文根据此演讲整理而成。
在物联网大数据时代,随着企业业务的不断扩张,需要采集的设备数量急剧上升,通常要达到百万甚至千万的级别,采集频率也从以前的 15分钟一个点逐渐演变到现在的 1分钟、30秒、15秒,甚至 1秒的一个点,这么多数据还要源源不断地发往云端,如何进行更好地写入、存储及查询,成为企业亟待解决的难题。
在测点数暴涨、数据采集频次不断提高的大数据时代,传统实时数据库暴露出下列问题:
没有水平扩展能力,如果数据量增加,只能依靠硬件 scale up
技术架构陈旧,使用磁盘阵列,大多运行在 Windows环境下
数据分析能力偏弱,不支持现在流行的各种大数据分析接口
不支持云端部署,更无法支持 PaaS
在此背景下,依靠 Hadoop架构形成的一系列通用数据存储解决方案,成为一众企业的首选,为了能够适配更多的业务场景,还要集成如 Kafka、Redis、Spark等众多第三方开源软件,在一次次的实践中,也暴露出诸多问题,如开发效率低、运行效率差、运维复杂以及应用推向市场慢等。
在此基础上,时序数据库(Time-Series Database)应运而生了。虽然新兴的时序数据库之间竞争激烈,但因为业务场景的复杂性和数据的多样性,还没有哪一款产品真正成为物联网场景的领跑者,而大部分产品还都存在以下三点难以忽视的问题:
功能单一,需要集成其他软件,提升系统负重及运维难度
不是标准 SQL,学习成本高
没有实现真正的云原生化,水平扩展能力有限
在调研了数百个业务场景的基础上,TDengine完成了 3.0版本的迭代,集群支持 10亿条以上的时间线、100台服务器节点,成为一款真正的云原生时序数据库,具有极强的弹性伸缩能力,且无需再集成 Kafka、Redis、Spark、Flink等软件,可以大幅降低系统架构的复杂度。
TDengine分布式系统架构设计
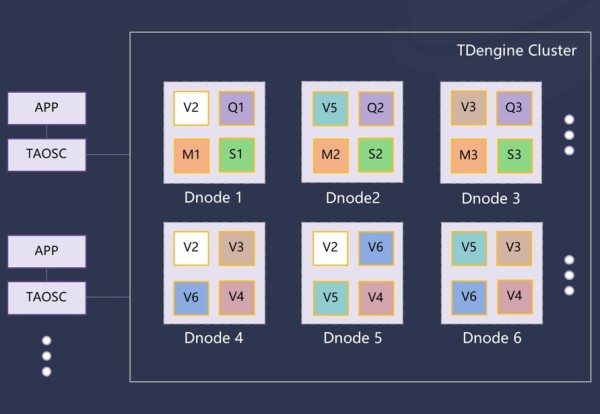
如上图所示,在数据节点(Dnode)、虚拟节点(Vnode)、管理节点(Mnode)之上,TDengine 3.0集群新增了弹性计算节点(Qnode)和流计算节点(Snode)。其中 Qnode主要在运行查询计算任务中起作用,当一个查询执行时,依赖执行计划,调度器会安排一个或多个 Qnode;Snode主要负责运行流计算任务,可以同时执行多个。
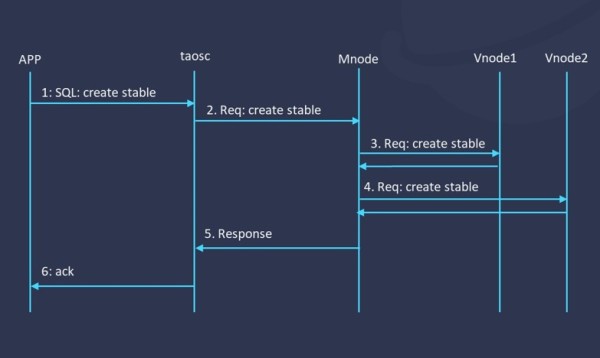
针对数据库级别的元数据管理,3.0版本通过两阶段提交来保证关键操作的一致性,以上图为例,假设我们要创建一张超级表,系统首先会把 SQL语句先解析成请求发给 Mnode,之后 Mnode会把这个请求发给各个不同的Vnode( Vnode1和 Vnode2),最后我们会等这些请求都结束之后再做一个持久化,然后把它返回给客户。
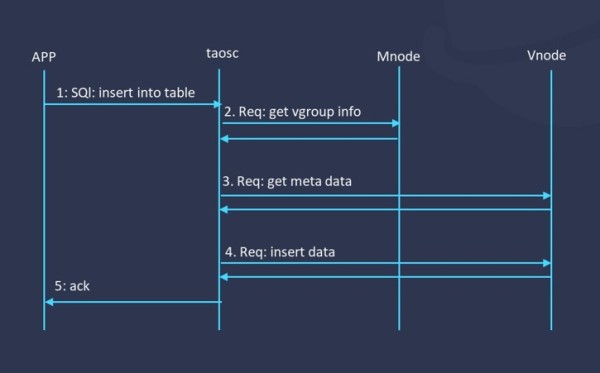
但在实际操作中,数据库级别的元数据,量是比较少的,更多的还是数据表级别的元数据管理。在以前的版本中,元数据都是集中管理,而 TDengine 3.0会把元数据都放到 Vnode里,在放弃中心节点之后,水平扩展能力显著提升。这样一来,当应用要将数据插入到一张表或对一张表做查询操作时,我们就可以基于表名的特定 hash值,将请求直接发送到对应的 Vnode里,性能可以得到进一步提升。
数据表中大量标签数据的处理也是一个重点,比如说一个设备的标签有 1K,那 100万个设备合在一起的话可能就会产生 1 GB的元数据,如果把它们都放在内存里,启动速度自然就会变得比较慢。
为了解决这个问题,新的版本采用了 LRU机制,只有使用比较频繁的数据才会被放在内存中。在全内存的情况下,对于千万级别规模的标签数据 TDengine能做到毫秒级的返回,那在内存资源不足的情况下,我们仍然能够支持数千万张表快速的查询。同时 TDengine还提供了 TTL机制,方便对一些只需要存储一个月或半年的数据,进行删除过期数据表的操作。
凭借着 LRU机制,TDengine的每一个 Vnode都能支持十万乃至百万以上数据表的管理。不同于 Prometheus,TDengine的每个数据表可以有很多个字段,这样的话假设说一个表有十个字段,我们就可以认为每个 Vnode可以支持百万的时间线。
此外,数据表路由的信息也是非常重要的。此前 TDengine每一条数据表的路由信息都需要在 Mnode做登记,再把登记的信息转给 Vnode,我们想要做的事务频率会越来越多,那可能就会导致每一个系统的 warmup时间越来越长。而且在刚开始部署一套系统时,就需要先把这些表都创建好,压力非常大。
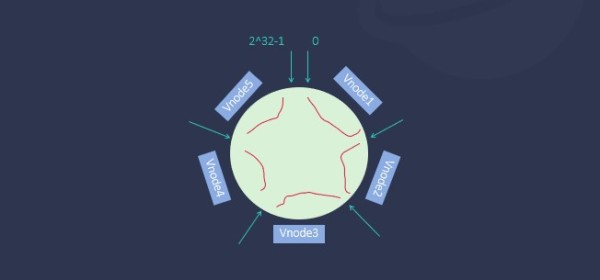
为了解决这个问题,TDengine 3.0做了一个特殊的创新,即数据表的路由采用一致性 hash算法,具体来说就是把数据表的名称压缩到 2的 32次方长度的一个环形空间,在创建 Database时就创建指定数目的 Vnode,系统就会按照等分的方法,把它拆解到这一环形空间中,每一个 Vnode就负责其中某一个 hash范围的数据表,并由 Mnode来负责 hash范围的管理。
在系统缩容、扩容时还可以通过动态调整 hash范围来实现,比如上面这个环形,我们想把 Vnode数量从 5个变成 6个,只需要调整其中某一个 Vnode的 hash范围就可以做到了,这样一来,TDengine就能够支持在 100个数据节点上创建 Vnode了。
大家可能会有一个疑问,如果用 hash会不会产生比较严重的数据倾斜,如果你只有一百个设备或者一千个设备,这种倾斜可能是比较严重的,这时你可以创建数目较少的 vgroup,最少可以设置一个,一个 vgroup包含 1-1000个数据表时,性能差别不大。当你达到一万个设备时,这种倾斜我们基本都看不出来了,数据是非常均匀分布的状态。
TDengine支持特定查询场景的性能调优
所有的查询性能也好,写入性能也好,本质上都是为了降低对硬盘的读写次数,如果存储量降下来了,那读取速度自然就可以获得更大的提升。一般来讲,一个硬盘的写入速度大概在 70 MB/s左右,读取速度可能在 100 MB/s,数据库没有办法突破这样一个物理上的瓶颈,那我们想要做到亿级数据或者十亿级数据这样一个秒级的查询计算,就必须想尽各种各样的方法对数据进行降采样,降低它的存储量。
从这一思路出发,在 TDengine 3.0中,我们也做了很多查询性能上的优化,具体体现在如下的三个功能上:
1.Block-Wise SMA(写入过程中,保存数据块的预计算结果)
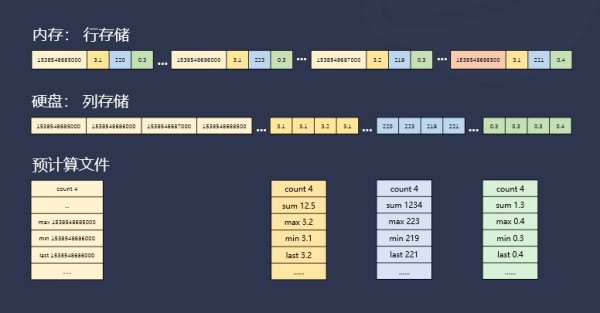
内存数据积累到一定大小触发写磁盘
由行存储转化为列存储
在磁盘中以数据块 Block形式组织
把 Block中各列数据的聚合结果,例如 max、min、sum、count等存储到 sma文件
根据查询计划选择使用哪些聚合结果
2.Rollup SMA(原始数据自动进行降采样存储)

支持三个不同的数据保存层级,指定每层数据的聚合周期和保存时长
level 1存储原始数据,可以在 level 1中存储一条或者多条数据,level 2和 3存储聚合数据
Rollup目前支持 avg, sum, min, max, last, first
适用于 DevOps等关注数据趋势的场景,本质是降低存储开销,加速查询,同时抛弃原始数据
3.Time-Range-Wise SMA(按照聚合结果降采样存储)
适用于高频使用 interval的查询场景
采用与普通流计算一样的逻辑,允许用户通过设定 watermark应对延时数据,相对应的实际的查询结果也会有一定的延迟
标签索引
我们在 3.0里也做了很多标签索引的优化,新实现了一个 TDB模块,特征就是把标签数据进行了 LRU的存储,这在前面也提到过。TDB的查询适用于标签变化不频繁或者说是有结构化标签的设备,例如文本型和数值类型。
对于 JSON类型的标签,特点是标签量很大但是数据内容很小,TDengine采用的就是 FST的索引方式。索引的重建一直是 FST里面比较复杂的部分,TDengine采用异步方式重建索引数据,因而不会让用户在创建表或者修改表时等待太长的时间。
对于数据缓存,虽然 TDengine 2.0也可以缓存最新的数据,但内存的消耗量会比较大,而在 3.0中用基础的 LRU库就可以把最近的数据放在内存里面,让用户即便用很小的内存,也可以查到最近使用比较频繁的数据。
计算资源弹性扩充
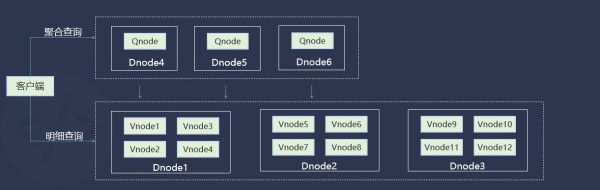
如上图所示,当客户端要进行明细数据查询时,需要先从磁盘里或者内存里源源不断地把原始数据读出来,这时我们肯定不希望这个数据要在不同节点里进行大量的数据交换,增加网络或磁盘开销,从这一点出发,TDengine将明细数据查询放在了 Vnode中进行。
但在做一些聚合查询(数据的计算、合并、插值等)时,比如说在车联网场景下要观察所有车辆每一天发动多长时间,这一类查询都是在 Qnode中进行,根据不同场景大家可以选择配置不同数量的 Qnode。
在时序场景下降低对 Kafka、Flink、Spark的依赖
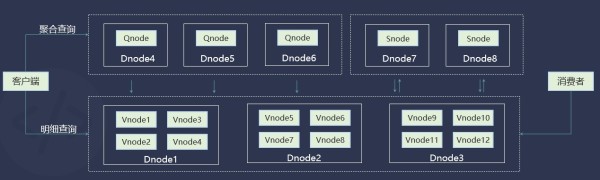
在时序场景下,TDengine降低了对 Kafka的依赖,我们的 Vnode可以允许不同的消费者同时消费数据,所有的数据都是结构化的数据,用户可以只订阅自己关注的这部分数据,比如说我只想关注电流里面超限的数据,使用 TDengine进行订阅时的数据传输总量非常小,但用 Kafka进行数据订阅时很可能需要从服务器拉取全部的数据,然后在客户端中进行数据筛选,这时两者的性能就完全不在一个量级上了。
此外,如果是常用的一些计算,还可以把它们放到 Snode里,Snode会将流计算的结果放到单独 Vnode里面去做存储,有了这样一个流计算的引擎,就大大降低了对 Flink和 Spark的依赖。
结语
TDengine 3.0的架构改进,从关键特性上来看,除了水平扩展性之外,还增强了弹性和韧性,可作为一个极简的时序数据处理平台,能够让大家以更低的成本完成时序数据平台的搭建。接下来我们还会陆续发布 TDCloud云服务版本、TDLite嵌入式版本,提供边云协同软件包、数据预测软件包,进一步提升系统高可用、高可靠、计算能力。
